
Votre serveur de fichiers est saturé à 95%. Votre certificat SSL expire dans 3 jours. La latence de votre base de données a doublé depuis ce matin. Sans supervision, vous ne découvrirez ces problèmes qu'au moment de la panne, quand vos utilisateurs seront déjà impactés. La supervision informatique transforme cette approche réactive en stratégie proactive.
Les risques d'une infrastructure non surveillée
Une PME sans monitoring navigue à l'aveugle. Les problèmes s'accumulent silencieusement jusqu'au point de rupture.
Pannes évitables
80% des incidents informatiques sont précédés de signaux d'alerte : espace disque qui diminue, mémoire qui sature, temps de réponse qui se dégrade. Sans surveillance, ces signaux passent inaperçus.
Temps de détection allongé
Sans monitoring, le temps moyen de détection d'un incident (MTTD) dépend des utilisateurs qui signalent le problème. Ce délai peut atteindre plusieurs heures, voire plusieurs jours pour les problèmes intermittents.
Coûts exponentiels
Selon le rapport EMA Research 2024 sur les coûts d'indisponibilité, le coût moyen d'une panne atteint 14 056 $ par minute, et monte à 23 750 $ pour les grandes entreprises. La bonne nouvelle : les organisations équipées d'outils AIOps rapportent une réduction significative de la fréquence et de la durée des pannes.
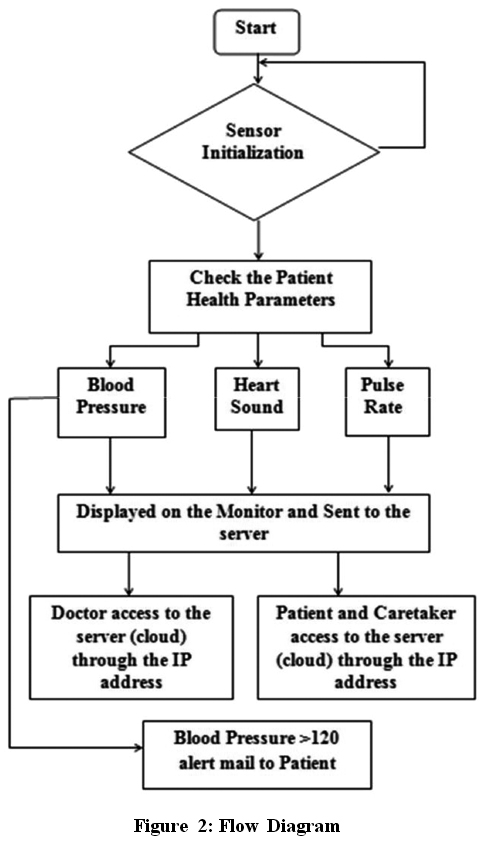
Les composants d'une supervision efficace
Une supervision complète couvre plusieurs couches de votre infrastructure.
Monitoring infrastructure
La couche la plus fondamentale surveille les ressources physiques et virtuelles :
Serveurs : CPU, mémoire, espace disque, température, état des disques (SMART).
Réseau : Bande passante, latence, perte de paquets, état des ports.
Stockage : Capacité, IOPS, santé des volumes RAID.
Monitoring applicatif
Au-delà de l'infrastructure, surveillez vos applications métier :
Disponibilité : L'application répond-elle ? En combien de temps ?
Performance : Temps de réponse des requêtes, taux d'erreur.
Métriques métier : Nombre de transactions, utilisateurs connectés.
Monitoring sécurité
La supervision inclut la détection des anomalies de sécurité :
Tentatives de connexion : Échecs répétés, connexions depuis des IP inhabituelles.
Modifications système : Fichiers critiques modifiés, nouveaux services démarrés.
Trafic réseau : Volumes anormaux, communications vers des destinations suspectes.
Outils de monitoring open-source
Les PME n'ont pas besoin de solutions coûteuses. L'écosystème open-source offre des outils puissants et matures.
Prometheus + Grafana
La combinaison la plus populaire en 2026. Prometheus collecte et stocke les métriques, Grafana les visualise dans des tableaux de bord élégants. Prometheus est un projet diplômé de la Cloud Native Computing Foundation, utilisé par des milliers d'entreprises dans le monde.
Points forts : Scalabilité, langage de requête puissant (PromQL), large écosystème d'exporters.
Cas d'usage : Idéal pour les infrastructures cloud-native et conteneurisées.
Zabbix
Solution tout-en-un mature, Zabbix est utilisée depuis plus de 20 ans par des organisations de toutes tailles, des PME aux entreprises du Fortune 500. Collecte, stockage, visualisation et alerting intégrés.
Points forts : Interface complète, découverte automatique, templates prêts à l'emploi.
Cas d'usage : Infrastructures traditionnelles, environnements hétérogènes.
Uptime Kuma
Solution légère et moderne pour le monitoring de disponibilité (uptime). Uptime Kuma s'installe en quelques minutes et offre une interface intuitive.
Points forts : Installation simple, notifications multi-canaux (Slack, Discord, Telegram, email).
Cas d'usage : Surveillance de sites web et APIs, PME avec ressources limitées.
| Outil | Type | Complexité | Idéal pour |
|---|---|---|---|
| Prometheus + Grafana | Métriques | Moyenne | Cloud, containers |
| Zabbix | Tout-en-un | Moyenne | Infra traditionnelle |
| Uptime Kuma | Disponibilité | Faible | Sites web, APIs |
Configurer des alertes intelligentes
Le monitoring sans alertes n'est qu'un tableau de bord décoratif. Mais trop d'alertes tuent l'alerte.
Éviter la fatigue d'alerte
Un système qui génère des dizaines d'alertes par jour finit par être ignoré. Chaque alerte doit correspondre à une action nécessaire.
Seuils pertinents : Un disque à 80% n'est pas une urgence. À 90%, c'est un avertissement. À 95%, c'est critique.
Agrégation : Regroupez les alertes liées. Si 10 services tombent en même temps, c'est probablement un problème réseau, pas 10 problèmes distincts.
Horaires : Certaines alertes peuvent attendre les heures ouvrées. D'autres nécessitent une intervention immédiate 24/7.
Canaux de notification
Adaptez le canal à l'urgence :
Email : Pour les avertissements non urgents, les rapports quotidiens.
Slack/Teams : Pour les alertes nécessitant une attention dans l'heure.
SMS/Appel : Pour les incidents critiques nécessitant une intervention immédiate.
Escalade
Si une alerte n'est pas acquittée dans un délai défini, elle doit escalader vers un niveau supérieur. Un incident critique ignoré pendant 30 minutes doit réveiller quelqu'un.
Tableaux de bord efficaces
Un bon dashboard raconte une histoire en un coup d'œil.
Principes de conception
Hiérarchie visuelle : Les informations les plus importantes en haut et à gauche. Les détails en dessous.
Couleurs significatives : Vert = OK, Orange = Attention, Rouge = Critique. Pas de couleurs décoratives.
Contexte temporel : Affichez les tendances, pas seulement les valeurs instantanées. Un CPU à 80% est-il en hausse ou en baisse ?
Dashboards par audience
Vue direction : Indicateurs de haut niveau. Disponibilité globale, incidents du mois, tendances.
Vue opérationnelle : État détaillé de chaque composant. Métriques techniques, alertes actives.
Vue investigation : Graphiques détaillés pour le diagnostic. Corrélations, historique long.
Supervision des sauvegardes
Les sauvegardes sont souvent le parent pauvre du monitoring. Pourtant, une sauvegarde qui échoue silencieusement est pire qu'une absence de sauvegarde.
Ce qu'il faut surveiller
Succès/échec : Chaque job de sauvegarde doit reporter son statut.
Durée : Une sauvegarde qui prend 3 fois plus de temps que d'habitude signale un problème.
Taille : Une sauvegarde anormalement petite peut indiquer des données manquantes.
Âge : Alertez si la dernière sauvegarde réussie date de plus de X heures.
Comme nous l'avons détaillé dans notre analyse sur les sauvegardes cloud, la vérification régulière des sauvegardes est particulièrement critique pour les entreprises des DOM-TOM exposées aux risques climatiques.
Supervision des certificats et licences
Les expirations sont prévisibles mais souvent oubliées.
Certificats SSL
Un certificat expiré bloque l'accès à votre site avec un avertissement effrayant. Surveillez l'expiration et alertez 30, 14 et 7 jours avant.
Licences logicielles
Certains logiciels cessent de fonctionner à l'expiration de la licence. Maintenez un inventaire avec dates d'expiration et alertes.
Domaines
Un domaine non renouvelé peut être récupéré par un tiers. Surveillez les dates d'expiration de tous vos domaines.
Mise en place progressive
Inutile de tout monitorer dès le premier jour. Procédez par étapes.
Phase 1 : L'essentiel (semaine 1-2)
• Disponibilité des services critiques (ping, HTTP)
• Espace disque des serveurs
• État des sauvegardes
Phase 2 : Performance (semaine 3-4)
• CPU et mémoire des serveurs
• Temps de réponse des applications
• Métriques réseau de base
Phase 3 : Approfondissement (mois 2)
• Métriques applicatives détaillées
• Logs centralisés
• Corrélation d'événements
Phase 4 : Optimisation (mois 3+)
• Affinage des seuils d'alerte
• Dashboards personnalisés
• Automatisation des réponses
Pour les entreprises qui souhaitent externaliser cette mise en place, des prestations de supervision et monitoring permettent de bénéficier d'une infrastructure de surveillance professionnelle sans investissement initial lourd.
FAQ : Supervision informatique
Quel budget prévoir pour le monitoring ?
Avec des outils open-source, le coût principal est le temps de mise en place et de maintenance. Comptez 2 à 5 jours pour une infrastructure de 10-20 serveurs, puis quelques heures par mois.
Faut-il surveiller 24/7 ?
La surveillance est automatique 24/7. La question est : qui reçoit les alertes critiques la nuit ? Pour une PME, un contrat d'astreinte avec un prestataire est souvent plus économique qu'une équipe interne.
Comment éviter les faux positifs ?
Affinez les seuils progressivement. Commencez large, puis resserrez en fonction de l'historique. Utilisez des moyennes mobiles plutôt que des valeurs instantanées.
Le monitoring ralentit-il les serveurs ?
L'impact est négligeable (moins de 1% de CPU) avec des outils bien configurés. Les bénéfices dépassent largement ce coût marginal.
Conclusion : voir pour anticiper
La supervision transforme votre approche de la maintenance informatique. Au lieu de subir les pannes, vous les anticipez. Au lieu de diagnostiquer à l'aveugle, vous disposez de données précises. Au lieu de réagir dans l'urgence, vous planifiez sereinement.
Les outils sont disponibles, souvent gratuits, et leur mise en place est accessible à toute PME. Le retour sur investissement est immédiat : moins de pannes, moins de stress, moins de pertes de productivité.
Commencez petit, avec les métriques essentielles, puis étendez progressivement votre couverture. Votre infrastructure vous remerciera.
Image : © Flickr, licence Creative Commons